Implementando o padrão Transactional Outbox
14 minutos de leitura
·#microservices-patterns
#distributed-systems
#code
Contexto
Imagine que você e seu time estão desenvolvendo um sistema baseado em microservices, em que diferentes serviços precisam se comunicar para atingir um objetivo em comum.
Dentre as opções de comunicação entre serviços — síncrona e assíncrona — vocês optaram primariamente pela comunicação assíncrona, utilizando o padrão Pub/Sub.
Além disso, vocês adotaram o padrão Database per Service, em que cada serviço é responsável pela persistência e manutenção de seus dados.
Nesse cenário, ao escrever em seu banco de dados, um serviço também precisa notificar os serviços interessados sobre o evento ocorrido.
Como garantir que a modificação no estado de uma entidade no banco de dados e o envio da mensagem associada acontecem de maneira atômica?
O código-fonte completo da implementação que veremos a seguir está disponível no repositório: https://github.com/joevtap/blog-demos/tree/main/transactional-outbox
Dual Write Problem
O problema surge justamente quando o serviço precisa realizar essas duas operações distintas de forma atômica (tudo ou nada):
- Escrever no banco de dados
- Publicar um evento no message broker
Se a operação no banco for bem-sucedida, a publicação do evento no message broker também precisa ocorrer com sucesso — caso contrário, o sistema pode entrar em um estado inconsistente.

No diagrama acima, a operação no banco aconteceu primeiro e com sucesso, mas ao escrever o evento no broker, ocorreu um erro de rede e o evento não pôde ser enviado mesmo após retries.

Publicar o evento primeiro também não funciona. O evento pode ser publicado com sucesso e a escrita no banco de dados falhar e tornar inválido o estado do sistema.
Uma possibilidade é utilizar soluções de transações distribuídas, como o padrão X/Open XA e Two-Phase Commit.
O problema é que esse tipo de solução precisa ser suportado tanto pelo SGBD, quanto pelo broker utilizados pelo sistema. Ainda, o Two-Phase Commit, é bloqueante, lento e complexo, não sendo viável para esse tipo de sistema.
Transactional Outbox
Outra solução — e o assunto deste post — é aproveitar as propriedades transacionais do SGBD relacional para resolver o problema diretamente no banco de dados.

No passo 1 do diagrama, ao inserir um pedido na tabela orders o serviço também insere o evento ORDER_PLACED na tabela outbox, as duas operações dentro da mesma transação.
Assim, ao ocorrer um commit, é garantido que tanto a mudança de estado quanto o evento correspondente foram persistidos com sucesso.
Eventualmente (passo 2 no diagrama), outro processo — que periodicamente consulta a tabela outbox — publica o evento no message broker.
Essa implementação do padrão Transactional Outbox é chamada de Polling Publisher, dada a natureza do processo que publica as mensagens (chamado de message processor ou message relay).
Implementando Polling Publisher
Essa abordagem é bastante flexível: funciona com qualquer SGBD relacional (e até alguns não relacionais) e qualquer sistema de mensageria.
No nosso caso, utilizarei o PostgreSQL como banco de dados e o NATS JetStream como message broker.
O serviço de pedidos e o message relay ficarão no mesmo processo: um programa escrito em TypeScript, rodando com Node. O serviço e o relay também podem ser colocados em processos separados.
Primeiro é preciso definir um schema para nosso banco de dados:
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
product_id INTEGER NOT NULL,
amount INTEGER NOT NULL,
status TEXT NOT NULL DEFAULT 'pending'::TEXT,
created_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW(),
updated_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW()
);
CREATE TABLE outbox (
id SERIAL PRIMARY KEY,
aggregate_id TEXT NOT NULL,
aggregate_type TEXT NOT NULL,
payload JSONB NOT NULL,
sequence_number INTEGER DEFAULT 0,
created_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW(),
processed_at TIMESTAMP WITHOUT TIME ZONE NULL,
UNIQUE (aggregate_id, sequence_number)
);As colunas aggregate_id e aggregate_type referem-se à nossa entidade order persistida na tabela orders. Essa nomenclatura vem do Domain Driven Design, que também tem suas associações com microservices.
A coluna payload contém o conteúdo da nossa mensagem, que normalmente dá o contexto do evento que deve ser conhecido pela parte interessada.
O campo sequence_number é importante para reordenar os eventos no consumidor caso eles cheguem fora de ordem (o que é comum e aceitável). A constraint UNIQUE apoia essa ideia.
Por fim, processed_at é importante para que o message relay saiba o que já foi processado.
Podemos criar um covered index para apoiar a consulta que o relay realizará periodicamente:
CREATE INDEX idx_outbox_unprocessed
ON outbox (processed_at, created_at)
INCLUDE (id, aggregate_id, aggregate_type, sequence_number, payload)
WHERE processed_at IS NULL;Um covered index inclui todos os campos necessários para a consulta no próprio índice, assim é possível realizar um index only scan, salvando um pouco de tempo na consulta.
Note que o índice também é parcial, visto que só indexamos os registros em que a coluna processed_at é NULL, ou seja, somente os eventos não processados pelo relay.
No handler do endpoint POST /orders da aplicação, executamos o insert em ambas as tabelas orders e outbox com o procedure placeOrder():
{
//...
handler: async (request, reply) => {
try {
await sql.begin(async (tx) => {
await placeOrder(tx, request.body);
reply.send({ message: "order placed" });
});
} catch {
// ...
}
},
// ...
}interface PlaceOrderProps {
productId: number;
amount: number;
}
export async function placeOrder(tx: TransactionSql, props: PlaceOrderProps) {
const { productId, amount } = props;
const [{ id: aggregateId }] = await tx`INSERT INTO orders (
product_id,
amount
) VALUES (
${productId},
${amount}
) RETURNING id`;
await tx`SELECT 1 FROM outbox WHERE aggregate_id = ${aggregateId} FOR UPDATE`;
const [{ max }] = await tx`
SELECT COALESCE(MAX(sequence_number), 0) AS max
FROM outbox
WHERE aggregate_id = ${aggregateId}
`;
const nextSequenceNumber = Number(max) + 1;
await tx`INSERT INTO outbox (
aggregate_id,
aggregate_type,
payload,
sequence_number
) VALUES (
${aggregateId},
'order',
${sql.json({
type: "ORDER_PLACED",
aggregateId,
aggregateType: "order",
sequenceNumber: nextSequenceNumber,
productId,
amount,
})},
${nextSequenceNumber}
)`;
}Incrementamos o sequence_number para cada alteração que fazemos no seu agregado. Inserir um pedido faz o contador subir de 0 (nenhum evento) para 1, com o evento ORDER_PLACED.
Para realizar esse incremento, primeiro um lock no registro do agregado em específico é obtido (utilizando o SELECT ... FOR UPDATE), isso evita condições de corrida.
Você pode apontar que existe repetição no que estou inserindo na tabela outbox, alguns campos da tabela são repetidos em JSON na coluna payload.
Isso é intencional para essa demonstração, visto que vou utilizar a mesma aplicação e schema do banco de dados para uma implementação alternativa ao “Polling Publisher” ainda neste post.
Polling da tabela outbox
Metade da solução já está implementada.
Ao alterar o estado de uma entidade no banco de dados, também cria-se o evento relacionado na tabela outbox, as duas operações dentro da mesma transação.
Agora é preciso enviar as mensagens da tabela outbox para o message broker, o que pode ser feito em um processo separado, visando separação de responsabilidades. Optei por fazer isso no mesmo processo do serviço.
export async function pollingPublisher() {
while (true) {
try {
await sql.begin(async (tx) => {
const events = await getEvents(tx);
await publishEvents(tx, events);
});
} catch (err) {
console.error(err);
}
await new Promise((resolve) => setTimeout(resolve, POLL_INTERVAL));
}
}Código bastante simples: um loop com um timeout no final, que é o intervalo do polling.
Mesmo o Node sendo single-threaded, essa função é não bloqueante por conta do async em sua definição.
A função getEvents() executa uma query na tabela outbox retornando as mensagens não processadas (aproveitando do índice que criamos previamente).
async function getEvents(tx: TransactionSql) {
return await tx`
SELECT id, aggregate_id, aggregate_type, payload, sequence_number
FROM outbox
WHERE processed_at IS NULL
ORDER BY created_at
LIMIT ${BATCH_SIZE}
FOR UPDATE SKIP LOCKED
`;
}Ordenamos pela coluna created_at e limitamos o resultado da query a uma quantidade arbitrária BATCH_SIZE de registros.
Novamente, essa query é executada com SELECT ... FOR UPDATE para que a transação obtenha um lock nos registros afetados, de modo a evitar condições de corrida.
O SKIP LOCKED evita que a transação fique bloqueada por outras transações afetando os mesmos registros. Isso é importante caso nosso processo seja escalado horizontalmente.
Por fim, publicamos os eventos obtidos:
async function publishEvents(tx: TransactionSql, events: RowList<Row[]>) {
if (events.length === 0) return;
for (const event of events) {
try {
await publishEvent(event.aggregate_type, {
id: event.id,
aggregate_id: event.aggregate_id,
aggregate_type: event.aggregate_type,
sequence_number: event.sequence_number,
payload: event.payload,
});
await tx`
UPDATE outbox
SET processed_at = NOW()
WHERE id = ${event.id}
`;
} catch (err) {
console.error(`Error when publishing event: ${err}`);
}
}
}Ao processar um evento, marcamos ele como processado atualizando a coluna processed_at com a timestamp do tempo atual do banco de dados.
Observe que essa operação NÃO é atômica. O UPDATE pode falhar depois do evento ser publicado — o que, em um retry, causaria um segundo envio do mesmo evento.
Isso é uma consequência esperada do padrão Transactional Outbox: eventos podem ser enviados mais de uma vez. Isso significa que a semântica de entrega das nossas mensagens é “ao menos uma vez” (at least once).
Os consumidores dessas mensagens devem garantir que uma mensagem duplicada não seja reprocessada, isto é, devem persistir um id das mensagens processadas e descartar duplicatas que podem chegar eventualmente.
Em outras palavras: os consumidores devem ser idempotentes.
Polling Publisher e seus trade-offs
Essa implementação possui algumas vantagens:
- É flexível.
- Pode ser implementada com poucas linhas de código.
- Independe de soluções de terceiros.
Mas também apresenta desvantagens:
- Introduz latência e consistência eventual (por si só, já um conjunto de trade-offs).
- Definir o intervalo do polling e o tamanho do batch ideais pode ser desafiador.
- O banco de dados pode se tornar um gargalo, já que precisa processar múltiplas leituras e escritas periodicamente.
Escalando o message relay horizontalmente
O message relay pode ser escalado horizontalmente de algumas maneiras.
Uma delas é introduzir um processo responsável por despachar os eventos da tabela outbox para um conjunto de relays, que então os processam. Essa abordagem funciona, mas introduz mais um bottleneck — além do próprio banco de dados.
Outra alternativa é simplesmente replicar o relay: executando múltiplas instâncias em paralelo, todas lendo diretamente da tabela outbox.

No entanto, o banco de dados continua sendo um gargalo, já que o polling exige tanto leituras quanto escritas frequentes, e não pode ser escalado horizontalmente com facilidade.
Além disso, não há garantia de ordenação global dos eventos.
Essa falta de ordenação global, porém, não deve ser vista como um problema sério, desde que o sistema seja projetado com operações comutativas sempre que possível, e que os consumidores estejam preparados para lidar com eventos fora de ordem.
Uma alternativa ao Polling Publisher: Transaction Log Tailing/Change Data Capture
Em vez de ter um processo periodicamente consultando a tabela outbox, é possível utilizar uma ferramenta de Change Data Capture (CDC), que consulta o Transaction Log do RDBMS para obter as alterações nas tabelas quase que em tempo real.
Uma ferramenta bastante utilizada com esse propósito é o Debezium.
Inicialmente, pensei em não trazer a implementação utilizando essa ferramenta porque acreditava que ela não integrava com outros brokers além do Apache Kafka, por meio do Kafka Connect.
Porém, existe uma versão standalone da ferramenta, o Debezium Server, que possui connectors para quase todas as soluções de mensageria e RDBMS mais conhecidas do mercado, incluindo o NATS JetStream, que estamos utilizando.
Como nem tudo são flores, a integração com o Apache Kafka é bem mais madura, permitindo escalabilidade horizontal e alto throughput.
Em um sistema de grande escala, utilizar o Apache Kafka como sink para o Debezium pode ser uma escolha inteligente, mas para o nosso caso, o Debezium Server com o NATS JetStream como sink é o suficiente.
O diagrama abaixo apresenta a implementação do Transactional Outbox utilizando o Debezium como ferramenta de CDC:

O Debezium se conecta ao PostgreSQL como source utilizando a chamada Logical Replication. É necessário configurar previamente o SGBD para permitir essa funcionalidade.
No nosso projeto de demonstração, isso é feito diretamente na configuração do serviço db no arquivo docker-compose.yaml:
db:
image: postgres:17.5-alpine3.21
# ...
command:
- "postgres"
- "-c"
- "wal_level=logical"O Debezium, portanto, não lê diretamente do PostgreSQL WAL (Write-Ahead Log), mas sim de um slot de replicação lógica que ele mesmo cria a partir de uma publication, também criada por padrão em sua primeira inicialização.
Como a implementação do Transactional Outbox utilizando CDC envolve mais configuração do que código, diferentemente da implementação utilizando polling, agora faz sentido mostrar a definição dos nossos serviços no arquivo docker-compose.yaml:
services:
orders:
build:
context: .
dockerfile: orders.Dockerfile
ports: [8080:8080]
environment:
BATCH_SIZE: 10
POLL_INTERVAL: 1000
STRATEGY: logtailing
DATABASE_URL: postgres://postgres:postgres@db:5432/demo
depends_on: [db, broker]
db:
image: postgres:17.5-alpine3.21
restart: unless-stopped
ports: [5432:5432]
volumes:
- ./docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d
- pgdata:/var/lib/postgresql/data]
environment:
POSTGRES_DB: demo
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
command:
- "postgres"
- "-c"
- "wal_level=logical"
broker:
image: nats:2.11.5-alpine3.22
ports: [4222:4222, 8222:8222]
volumes:
- natsdata:/data
command:
- "--js"
- "--sd=/data"
restart: unless-stopped
debezium:
image: quay.io/debezium/server:3.2
ports: [8081:8080]
volumes:
- ./debezium-conf.d/:/debezium/config/
- debeziumdata:/debezium/data
depends_on: [db, broker]
volumes:
pgdata:
natsdata:
debeziumdata:Os serviços broker, db e orders já estavam presentes para nossa implementação com polling. O debezium foi adicionado para a implementação com CDC.
O arquivo debezium-conf.d/application.properties define a configuração do Debezium necessária para seu funcionamento como message relay.
quarkus.log.console.json=false
quarkus.log.level=INFO
debezium.sink.type=nats-jetstream
debezium.sink.nats-jetstream.url=nats://broker:4222
debezium.sink.nats-jetstream.create-stream=true
debezium.sink.nats-jetstream.subjects=outbox,outbox.>
debezium.source.connector.class=io.debezium.connector.postgresql.PostgresConnector
debezium.source.offset.storage.file.filename=/debezium/data/offsets.dat
debezium.source.offset.flush.interval.ms=0
debezium.source.database.hostname=db
debezium.source.database.port=5432
debezium.source.database.user=postgres
debezium.source.database.password=postgres
debezium.source.database.dbname=demo
debezium.source.topic.prefix=outbox
debezium.source.plugin.name=pgoutput
debezium.source.table.include.list=public.outbox
debezium.source.snapshot.mode=initial
debezium.transforms=outbox
debezium.transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
debezium.transforms.outbox.table.expand.json.payload=true
debezium.transforms.outbox.table.field.event.key=aggregate_id
debezium.transforms.outbox.route.by.field=aggregate_type
value.converter=org.apache.kafka.connect.json.JsonConverterMuita configuração, não é mesmo? Isso talvez seja uma das desvantagens da utilização de uma ferramenta de CDC: o setup inicial é bem mais complexo que a contraparte que só precisa de algumas linhas de código para funcionar.
Algumas propriedades importantes para o nosso setup:
debezium.source.plugin.name=pgoutputdefine o plugin de decodificação do WAL utilizado pelo PostgreSQL para a replicação lógica. Opgoutputé o padrão, não é tão performático mas exige menos configuração da nossa parte.debezium.source.topic.prefix=outboxedebezium.sink.nats-jetstream.subjects=outbox,outbox.>devem definir o mesmo tópico/subjectoutbox(ou outro nome).- A segunda propriedade é usada pelo connector do NATS JetStream para criar os tópicos
outboxeoutbox.>(um wildcard) na stream reservada para o Debezium.
- A segunda propriedade é usada pelo connector do NATS JetStream para criar os tópicos
- As propriedades que começam com
debezium.transformsedebezium.transforms.outboxdefinem uma transformation que será realizada pelo Debezium quando capturar alguma alteração nas tabelas definidas emdebezium.source.table.include.list.- Essa transformation
outboxé responsável por rotear as mudanças na nossa tabelapublic.outboxpara o devido tópico do NATS JetStream (propriedadedebezium.transforms.outbox.route.by.field=aggregate_type).
- Essa transformation
Você pode ver detalhes dessa configuração nos seguintes links da documentação do Debezium:
- https://debezium.io/documentation/reference/stable/connectors/postgresql.html
- https://debezium.io/documentation/reference/stable/operations/debezium-server.html#_nats_jetstream
- https://debezium.io/documentation/reference/stable/transformations/index.html
- https://debezium.io/documentation/reference/stable/transformations/outbox-event-router.html
Depois de fazer toda essa configuração, temos o Debezium capturando inserts na tabela outbox e roteando nossos eventos para o subject outbox.> no NATS JetStream.
Um consumidor interessado nos eventos do aggregate order se inscreveria no subject outbox.event.order, por exemplo. O resultado é o seguinte:
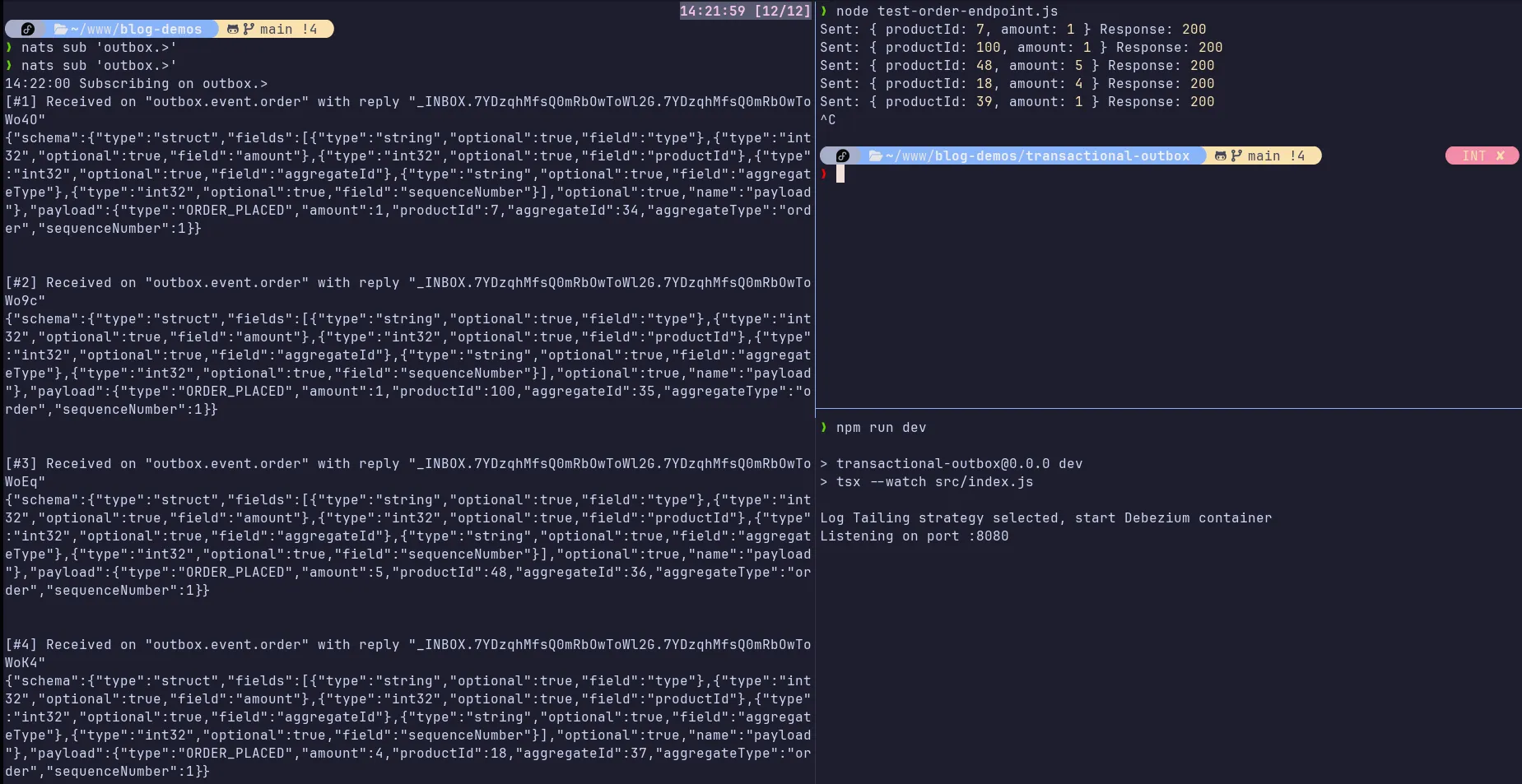
Transaction Log Tailing/Change Data Capture e seus trade-offs
Essa abordagem possui algumas vantagens em relação à anterior:
- Maior confiabilidade, por utilizar a replicação lógica do PostgreSQL.
- Melhor desempenho, já que não sobrecarrega o banco com leituras e escritas frequentes.
- Production readiness, o Debezium é amplamente adotado no mercado para esse propósito.
- Alta escalabilidade, especialmente quando integrado ao Apache Kafka via Kafka Connect, permitindo escalabilidade horizontal e alto throughput.
Por outro lado, também traz algumas desvantagens:
- Setup inicial mais complexo, especialmente quando envolve gerenciar um cluster do Apache Kafka.
- Requer um processo separado e relativamente pesado (o Debezium).
- Introduz uma dependência externa, mesmo que seja uma ferramenta consolidada no mercado.
Conclusão
Neste post, apresentei um problema clássico no contexto de sistemas distribuídos e microservices: o Dual Write Problem, e explorei duas abordagens baseadas no padrão Transactional Outbox para resolvê-lo.
Vimos que, quando o uso de transações distribuídas como Two-Phase Commit ou X/Open XA não é viável (seja por complexidade ou falta de suporte), o Transactional Outbox se torna uma alternativa prática e eficaz.
Embora não seja a única solução — arquiteturas orientadas a eventos também podem recorrer ao Event Sourcing, por exemplo — o padrão Transactional Outbox é útil em cenários em que eventos como source of truth só resultaria em complexidade desnecessária.
A escolha entre as abordagens apresentadas (Polling Publisher vs. Trasaction Log Tailing/Change Data Capture) depende de diversos fatores do contexto: escala, complexidade operacional, requisitos de latência, entre outros. Por isso, me preocupei somente em destacar os trade-offs de ambas as abordagens para que você possa fazer uma decisão informada.
A implementação demonstrada aqui é simplificada e não está pronta para produção. Faltam aspectos importantes como monitoramento e observabilidade, além de outros mecanismos de resiliência como Dead-Letter Queue.
Como próximo passo, seria interessante incorporar testes de performance. Fico aberto a feedbacks, críticas e contribuições para a melhoria deste conteúdo.
Referências
- https://microservices.io/patterns/data/transactional-outbox.html
- https://microservices.io/patterns/data/polling-publisher.html
- https://microservices.io/patterns/data/transaction-log-tailing.html
- https://microservices.io/patterns/data/event-sourcing.html
- https://ederfmatos.medium.com/implementando-transactional-outbox-com-go-dynamodb-mongodb-kafka-e-rabbitmq-7d2c4a7db7d8
- https://medium.com/@xavier_jose/transactional-outbox-pattern-implementation-fa3de00ceba5
- https://eskelsen.medium.com/aplicando-transactional-outbox-pattern-com-debezium-postgresql-e-gcp-pub-sub-para-eliminar-a4b9f858416c
- https://dev.to/fairday/implementing-horizontally-scalable-transactional-outbox-pattern-with-net-8-and-kafka-a-practical-guide-1l1
- https://yektaus.medium.com/using-change-data-capture-and-polling-publisher-in-the-transactional-outbox-pattern-cac5ced14faf